李沐
- 机械学习 本身是 一个压缩算法
- 模型深比浅更好(同等计算时)
- 一般高宽减半,通道数✖️2
- 深度学习模型拟合复杂数据的核心在于非线性激活函数(如 ReLU)。网络越深,非线性越强,表达能力就越强。
- 空间信息(卷积层、池化层),通道数(1✖️1卷积变化)
- 计算不要用for-loops,性能差(pthon)
- 批量大小—-尽量小于数据集中类的10倍
- 学习率调节 : 先大的学习率跑,如果发现验证集损失变平时,停掉训练,用小一点的学习率
- pytroch会把小矩阵变成大矩阵来提高计算速度
提升精度
数据方面
- 数据增广—-单图增强,跨图片增强(Mixup–随机叠加图片;CutMix–随机组合来自不同图片的块)
- 测试时数据增强
模型方面
- 模型变种/融合
- 优化算法—Adam/变种
- 学习率Cosine调节/训练不变时调节
工业界
- 少使用模型融合、测试时增强,计算代价高
- 固定超参数,将精力主要花在提升数据质量
LP线性规划
LP 一般指 Linear Programming,线性规划:在一组线性约束下,最大化或最小化一个线性目标函数。
最经典算法是单纯形法,现代大规模问题常用内点法。
detach()
PyTorch 的 detach() 用来把张量从自动求导计算图中分离出来,让它后续不参与梯度传播;但它通常仍和原张量共享内存。
forward()前向计算
def forward(...) 是 PyTorch 模型里定义前向计算逻辑的函数;当你执行 model(x) 时,它会被自动调用。__init__ 负责“模型里有什么”,forward 负责“数据怎么流过去得到输出”,backward 负责“根据损失把梯度往回传”。
一个很直观的类比,你可以这样记:
__init__:搭机器forward:机器加工输入backward:根据结果倒推哪里该改optimizer.step():真的去拧螺丝、调参数__init__:对象创建时调用一次 dataset = MyDataset(data)__getitem__:取某个样本时调用 loader = DataLoader(dataset, batch_size=4, shuffle=True) dataset[idx]forward:模型接收输入做前向传播时调用 output = model(x)
Softmax 激活函数
是把一组实数分数转换成概率分布的函数。
输出值都大于 0 且总和为 1,常用于多分类任务的输出层。
它通过指数运算突出较大分数,使模型能更清楚地表达对各类别的偏好;
训练时通常配合交叉熵损失直接使用 logits,
而在推理或展示结果时再用 Softmax 将分数转成可解释的概率。

logits:模型最后输出的原始分数
softmax 输出:归一化后的概率
Softmax:给出每个类别的概率
argmax:选出最大值对应的类别下标
损失函数
是机器学习中用来衡量模型预测结果与真实标签之间差异的函数,它把误差转化为一个可计算、可优化的数值,并为参数更新提供方向。
回归任务中常用 MSE、MAE 等损失函数—–一个输出标量



分类任务中常用交叉熵损失


训练的本质就是通过反向传播和优化器不断减小损失,使模型预测越来越接近真实结果。
感知机
单层感知机
感知机是最早的人工神经元模型之一,可以看成是:
对输入做加权求和,再根据结果做二分类判断。
感知机适合解决:线性可分的二分类问题。
所谓线性可分,就是:能够用一条直线(二维)、一个平面(三维)或超平面(更高维)把两类样本分开。
XOR 问题
XOR 是“异或”(exclusive OR)。
它的规则是:
- 两个输入不同,输出 1
- 两个输入相同,输出 0
不是线性可分的
XOR 问题证明了单层感知机只能处理线性可分问题,不能处理非线性可分问题。
多层感知机(MLP)
没有激活函数,多层感知机即使堆很多层,整体也还是近似一个线性变换。
多层感知机是由多个神经元层层堆叠组成的前馈神经网络,通常包括:
- 输入层
- 一个或多个隐藏层
- 输出层
它的基本结构可以写成:
x→隐藏层1→隐藏层2→⋯→输出层x
每一层都会对上一层输出做两步操作:
- 线性变换
- 非线性激活
把很多个感知机按层连接起来。
单层感知机只能解决线性可分问题,而多层感知机通过增加隐藏层和非线性激活,可以学习更复杂的非线性关系。
所以多层感知机相对于单层感知机的提升主要在于:
- 层数更多
- 表达能力更强
- 能处理非线性问题
常见激活函数
Sigmoid

Tanh

ReLU(使用较多)

Leaky ReLU

Softmax(常用于输出层)

标签平滑(Label Smoothing)
将分类任务的真实标签(Target)从绝对的 [1, 0] 修改为 [0.9, 0.1] 的操作,在深度学习中被称为标签平滑(Label Smoothing)。
这是一种非常简单但极其有效的正则化技术,广泛应用于各种先进的图像分类(如 Inception、ResNet 等)和自然语言处理(如 Transformer 机器翻译)模型中。
它的核心好处可以概括为两点:防止过拟合(防止模型过度自信) 和 提高模型的泛化与容错能力。
[1, 0]
数学灾难:无限大的 Logit
Softmax 的公式为 $P_i = \frac{e^{x_i}}{\sum e^{x_j}}$。
如果真实标签是 1,模型为了让交叉熵损失降到绝对的 0,它必须输出概率 1.0。
但是,根据 Softmax 公式,只有当正确类别的得分(Logit)比其他类别的得分大无限倍(无穷大)时,输出概率才会等于 1.0。
这会导致两个严重后果:
过度自信(Overconfidence): 模型会不顾一切地增大正确类别的权重,不断拉大类间得分差异。这会让模型对自己的预测“过于肯定”,即使遇到极其模糊的图片也敢给出 99.9% 的概率。
极易过拟合(Overfitting): 因为模型永远达不到绝对的 1.0,即使它已经分类正确了(比如输出了 0.95),交叉熵损失依然存在。模型会继续拼命榨取训练集里的每一个像素细节来放大权重,最终“死记硬背”了训练集,导致在测试集上表现糟糕。
[0.9, 0.1]
1. 截断了权重的无限扩张(权重正则化)
如果目标概率是 0.9,模型不需要把正确类别的得分推向无穷大。
在二分类中,为了让 Softmax 输出 0.9,正确类的 Logit 只需要比错误类大 $2.19$(因为 $\ln(0.9/0.1) \approx 2.19$)就足够了。
一旦得分差达到 2.19,模型就不再受到惩罚(Loss 达到理论最低点)。这就相当于给网络权重加上了一个“刹车”,防止了参数的无限膨胀。
2. 惩罚“盲目自信”
这是标签平滑最反直觉但也最神奇的地方:如果你让目标是 0.9,当模型输出 0.99 的概率时,它的 Loss 反而会变大!
模型被明确告知:“你只要有 90% 的把握就行了,如果你表现得 99% 确定,那说明你武断了,我要惩罚你。” 这迫使模型保持谦逊,保留一定的“犹豫空间”,从而大幅提升泛化能力。
3. 增强对标注噪声的容错率
现实中的数据集经常有标错的图片(比如把狗标成了猫)。如果是 [1, 0],模型会被这个错误标签严重误导,拼命去学这个错误特征。如果是 [0.9, 0.1],模型实际上在承认“人类给的标签也只有 90% 的可信度,还有 10% 可能是别的东西”,这极大降低了错误标签对网络结构的破坏。
小结
可以把 MLP 看成下面这个重复结构:
线性层→激活函数→线性层→激活函数→⋯
也就是说:
- 线性层负责特征组合
- 激活函数负责引入非线性
- 两者配合才能形成真正强大的模型
如果少了激活函数,MLP 就失去了“深度”的意义。
多层感知机(MLP) 是由输入层、一个或多个隐藏层和输出层组成的前馈神经网络,
每一层通常包含线性变换和激活函数。线性层负责对特征进行加权组合,激活函数负责引入非线性,使网络能够学习复杂的非线性关系;如果没有激活函数,多层网络本质上仍等价于单层线性模型。
常见激活函数有 Sigmoid、Tanh、ReLU 和 Softmax,其中 ReLU 常用于隐藏层,Softmax 常用于多分类输出层。
模型选择
训练集、验证集、测试集
一个常见流程是:
- 用训练集训练模型
- 用验证集调超参数、选最佳模型
- 最后用测试集报告最终结果
也就是:
- 训练集:用于学习参数
- 验证集:用于调参和模型选择
- 测试集:用于最终无偏评估
为什么“有时不用 test”最本质的原因
- 数据太少,切不出足够独立的 test
- 还在开发阶段,test 故意留到最后
- 有其他评估方式替代了显式 test,比如交叉验证或隐藏测试集
误差
训练误差(training error) 是指模型在训练集上的误差。
模型是否把训练数据拟合好了。
泛化误差(generalization error) 是指模型在新的、未见过的数据上的误差。
模型从已知数据推广到未知数据的能力。
常见估计方式包括:
- 验证集
- 测试集
- 交叉验证
这时得到的其实是对泛化误差的近似估计。
训练误差≤泛化误差
过拟合和欠拟合
模型容量小难以拟合复杂的训练数据,容量大会记住所有的训练数据
欠拟合(underfitting)
表现是:
- 训练误差高
- 泛化误差也高
说明模型太弱,连训练数据都没学好。
过拟合(overfitting)
表现是:
- 训练误差很低
- 泛化误差较高
说明模型把训练数据学得太死,甚至把噪声也记住了,导致对新数据表现不好。
理想情况
- 训练误差较低
- 泛化误差也较低
- 两者差距不大
这说明模型既学到了训练数据,也具备较好的推广能力。
k 折交叉验证
把数据分成 k 份,轮流拿其中 1 份做验证,其余 k-1 份做训练,最后把 k 次结果平均。
k 折交叉验证通过多次轮换:
- 让每个样本都有机会做验证样本
- 减少单次划分带来的偶然性
- 让评估结果更稳定、更可靠
在有限数据条件下,更可靠地估计泛化误差
- 5 折交叉验证
- 10 折交叉验证
长尾问题(Long Tail Problem)
指在某些数据分布中,少数类 别(或事件)出现的频率非常高,而多数类别(或事件)出现的频率非常低。
解决长尾问题的关键在于如何有效地处理这些低频类别,以充分利用长尾部分的数据价值。
模型容量
模型拟合各种函数、各种模式的能力强弱。 你可以把它理解成模型的“表达能力”或“灵活程度”。
要和任务复杂度、数据规模相匹配。
参数越多,模型容量越大,但两者不完全等价**。
因为模型容量不仅取决于:
- 参数个数
- 还取决于模型结构
- 激活函数
- 正则化方式
- 参数共享机制
模型复杂度(Model Complexity)核心知识点
概念定义: 衡量模型学习复杂映射关系能力的指标。复杂度越高,模型“容量”越大,但也越容易失控。
三大衡量维度:
空间复杂度: 模型参数的数量(决定内存/显存占用)。
时间复杂度: 浮点乘加运算的次数(FLOPs/MACs,决定推理速度)(模型深度)。
表征复杂度: 假设空间的广度(决定决策边界的曲折程度)。
不一定模型参数的数量小,计算快
核心矛盾(偏差-方差困境):
复杂度过低 $\rightarrow$ 欠拟合(高偏差): 模型学不到基本特征。
复杂度适中 $\rightarrow$ 最优泛化: 模型学到了底层规律,且对新数据适应性好。
复杂度过高 $\rightarrow$ 过拟合(高方差): 模型死记硬背了训练集里的随机噪声,导致测试准确率暴跌。
VC维
是统计学习理论中一个非常经典的概念,用来衡量:一个二分类模型能把多少个点“任意地分对”。
在样本数固定时,模型复杂度越高,泛化风险通常越大。
VC 维就是复杂度的一种度量。
如果 VC 维很高,而训练样本又不够多,那么模型可能在训练集上拟合很好,但在新数据上不稳定。
数据复杂度
数据复杂度 指的是:数据中的规律有多复杂、分类边界有多难、噪声有多少、样本分布有多混乱。
也就是说,它描述的不是模型,而是:任务本身难不难。
情况 1:低容量模型 + 高复杂数据
模型学不会,会欠拟合
情况 2:高容量模型 + 简单数据 + 样本少
模型可能学得太细,把噪声也学进去,容易过拟合。
情况 3:容量和复杂度匹配
模型既能抓住规律,又不会太过头,效果通常最好。
所以一个很重要的思想是:
模型选择,本质上是在让模型容量与数据复杂度相适应。
模型容量表示模型拟合复杂规律的能力,容量越大,模型能表示的函数越复杂,但也更容易过拟合;VC 维是统计学习理论中衡量模型容量的一种经典指标,表示模型类能够将样本任意二分类并完全分开的最大样本数;数据复杂度则描述任务本身规律的复杂程度,包括决策边界、噪声、类间重叠等因素。机器学习中需要让模型容量与数据复杂度相匹配:容量太小会欠拟合,容量太大会过拟合,只有匹配得当,模型才更容易获得良好的泛化能力。
正则(regularization)控制模型复杂度,防止过拟合
正则 是一类方法的总称,目的就是:
在训练模型时,除了让模型拟合训练数据,还额外加一些约束,防止模型学得过于复杂,从而减少过拟合。
软性限制
不是强行规定参数必须满足某个硬条件,而是在目标函数里加一个惩罚项,让某些不希望出现的解代价更高
硬性限制
例如直接规定: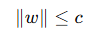
必须满足,否则不允许。
软性限制
例如把约束写进损失函数:
对最优解的影响
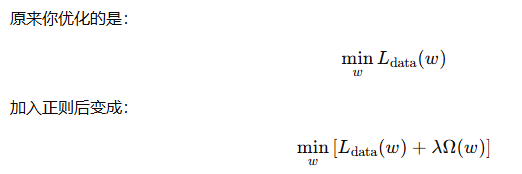
最优解不再只是“训练误差最小”的解,而是“训练误差和模型复杂度折中后最合适”的解。
权重衰退(weight decay)
权重衰退 是最经典的正则化方法之一,通常对应 L2 正则化。
它的思想是:在损失函数中惩罚权重过大。
L1正则
丢弃法(Dropout)
在训练时,随机把一部分神经元输出置为 0,不让它们参与当前这次前向传播。
训练时不要太依赖某几个固定神经元,而是逼着网络学出更稳健、更分散的表示。
训练时 随机丢弃部分神经元。
测试时 不丢弃,使用完整网络,但会做相应缩放处理。
所以 Dropout 只是在训练阶段引入随机扰动,测试时正常使用全部单元。
全连接层(Fully Connected Layer)
当前层的每个神经元都与前一层的所有神经元相连。
优点:
- 表达能力强
- 可以充分混合所有输入特征
- 很适合做最后的分类或回归
缺点:
- 参数很多
- 容易过拟合
- 对输入空间结构利用不高
例如图像任务中,如果直接对大图像用全连接层,参数会爆炸。
所以全连接层往往放在网络后部,用于“综合特征后做决策”。
卷积层(Convolution Layer)
卷积层 是专门为图像、时序、局部结构数据设计的一类层。
它不是“每个输出都连接所有输入”,而是:通过一个小的卷积核,在局部区域上滑动提取特征。
局部连接
只看输入的局部邻域,而不是全局全部连接。
参数共享
同一个卷积核在不同位置重复使用。
这两个特性使得卷积层:
- 参数更少
- 更适合提取局部模式
- 对平移更稳定
- 更不容易过拟合
数值稳定性
在计算机用有限精度做运算时,模型训练过程是否容易出现异常数值问题
数值稳定,就是训练过程中数值不要乱飞。
训练稳定性本质上是:
前向传播和反向传播中的数值幅度是否被控制在合理范围内。
梯度爆炸
在反向传播时,链式求导中多个较大因子相乘,导致梯度迅速放大。
梯度消失
在反向传播时,链式求导中多个小于 1 的因子连续相乘,导致梯度越来越小。
模型初始化
初始化 决定了训练开始时参数落在什么位置。
如果初始化不合适,网络一开始就可能进入不稳定状态。
好的初始化希望做到:
- 每层输出方差不要变化太大
- 梯度在反向传播时不要急剧放大或缩小
Xavier 初始化
适合tanh、sigmoid一类激活函数,目标是让前向和反向的方差比较稳定。
He 初始化
更适合ReLU及其变体,因为 ReLU 会把一部分信号截断为 0,所以需要稍微不同的方差设定。
让训练稳定的常见做法
- 合理初始化
- 选择合适激活函数(隐藏层常用 ReLU / Leaky ReLU / GELU;少用 sigmoid 作为深层隐藏层激活)
- 使用较小学习率
- 梯度裁剪(把梯度裁剪到某个阈值以下;常用于 RNN、Transformer 等容易梯度爆炸的模型)
- 数据标准化 / 归一化(输入归一化;BatchNorm;LayerNorm)
传播
- 先前向传播得到结果
- 计算损失
- 再反向传播更新参数
前向传播
- 前向传播:从输入到输出,算预测值
前向传播就是神经网络利用当前参数,把输入数据逐层计算并最终得到输出结果的过程。
PyTorch 里:
1 | model(x) |
等价于:
1 | model.__call__(x) |
而 nn.Module.__call__() 内部最终会去调用这个模型类自己的 forward()。
反向传播
- 反向传播:从损失往回传,算梯度,更新参数
模型
- 模型构造决定网络长什么样、数据如何流动
- 参数管理决定网络中的可学习量如何组织、初始化、更新和控制
- 自定义层让你能突破标准模块限制,构造更灵活、更贴合任务的模型
- 读写文件保证模型、参数和实验状态可以保存、恢复、迁移和部署
深度学习中的模型构造,本质上是把多个层和运算按一定逻辑组织成一个可学习函数;
参数管理则负责这些可学习变量的定义、初始化、共享、冻结、更新与保存;
自定义层使研究者和工程师能够超越框架内置模块,自由实现新的计算单元和结构;
而读写文件则保证模型参数、训练状态和实验配置能够被持久化、恢复、迁移和部署。
数据预处理GPU
数据预处理什么时候放 GPU”,那要分两类:
- 读文件、解析、Python/Numpy/OpenCV 预处理:通常还是放 CPU
- 归一化、tensor 变换、部分增强,如果是 PyTorch tensor 操作:可以在 to_device 之后放 GPU 上做
通常时机就是:
- DataLoader 先在 CPU 上把一个 batch 准备好
- 进入训练循环后,把这个 batch 搬到 GPU
- 再前向、算 loss、反向传播
所以一般不是“把整个数据集放进 GPU”,而是“每次把当前 batch 放进 GPU”。
One-Hot编码
One-Hot编码,也称为独热编码
One-Hot编码的核心思想是将分类变量转换为二进制(0或1)向量。对于每个特征,我们创建一个与可能的类别数量相同的位数的向量。每个类别由一个位表示,当该类别出现时,相应的位设为1,其余位设为0。例如,对于颜色特征,红色可以编码为[1, 0, 0],绿色为[0, 1, 0],蓝色为[0, 0, 1]。
One-Hot编码的优点在于它能够将分类数据转换为机器学习算法可以处理的格式,同时避免了不同类别之间可能引入的数值大小关系。然而,它也有缺点,比如当类别数量很多时,会导致特征空间的维度剧增,可能会引起维度灾难,增加模型的复杂度和过拟合的风险。
卷积(Convolutional Neural Networks)
全连接层(Fully Connected Layer)面临的困境
在全连接网络(多层感知机,MLP)中,每一层的输出是输入的线性组合加上偏置。如果我们用一张二维图像作为输入,网络会将图像展平为一维向量。
假设输入图像 $\mathbf{X}$ 的大小为 $H \times W$,输出隐藏层 $\mathbf{Y}$ 的大小也是 $H \times W$。在全连接层中,输出的每个神经元 $Y_{i,j}$ 都与输入的每一个像素 $X_{k,l}$ 相连。用权重张量 $\mathbf{W}$ 表示,可以写成:
$$Y_{i,j} = \sum_{k=1}^{H} \sum_{l=1}^{W} W_{i,j,k,l} X_{k,l}$$
致命问题:参数爆炸。
如果图像是一张 $1000 \times 1000$(即100万像素)的高清图,隐藏层也有100万个神经元,那么仅仅这一层的权重 $\mathbf{W}$ 就需要 $10^{12}$ 个参数。这在计算和存储上都是不可接受的,而且极易导致过拟合。
核心假设一:局部性(Locality)
直觉: 要识别图像中的一个特征(例如猫的眼睛、桌子的边缘),我们不需要观察整张图像,只需要观察该特征所在的一小块局部区域即可。
数学表达:
为了方便描述,我们引入偏移量 $a$ 和 $b$,令 $k = i+a$,$l = j+b$。那么全连接层的公式可以改写为:
$$Y_{i,j} = \sum_{a} \sum_{b} W_{i,j, i+a, j+b} X_{i+a, j+b}$$
引入“局部性”原则后,我们认为距离 $(i,j)$ 较远的输入像素不应该影响 $Y_{i,j}$ 的值。也就是说,当 $|a| > \Delta$ 或 $|b| > \Delta$ 时,权重为零。$\Delta$ 是一个相对较小的常数(例如,定义一个 $3 \times 3$ 的感受野时,$\Delta = 1$)。
此时,网络公式简化为:
$$Y_{i,j} = \sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta} W_{i,j, i+a, j+b} X_{i+a, j+b}$$
此时,参数量已经大幅减少,每个输出神经元只和输入的一小块区域(感受野)相连。
核心假设二:平移不变性(Translation Invariance)
核 不变
直觉: 无论一只猫出现在图像的左上角还是右下角,它都是一只猫。检测猫的特征(或者说识别模式)的方法,不应该因为该特征在图像中的位置改变而改变。
数学表达:
在加入了局部性的公式中,$W_{i,j, i+a, j+b}$ 表示为了计算位置 $(i,j)$ 的输出,我们如何对偏移量为 $(a,b)$ 的输入进行加权。
平移不变性意味着,这个权重不应该依赖于具体的绝对位置 $(i,j)$,它应该在整张图像上共享。因此,我们可以将 $W_{i,j, i+a, j+b}$ 简写为只依赖于偏移量的 $V_{a,b}$。
将 $V_{a,b}$ 代入公式,我们得到:
$$Y_{i,j} = \sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta} V_{a,b} X_{i+a, j+b}$$
这正是标准的二维离散交叉相关(Cross-Correlation)公式,也就是深度学习中所说的二维卷积(Convolution)! 其中,$V$ 就是卷积核(Convolutional Kernel)或滤波器(Filter)。
卷积层(Convolutional Layer)
通过引入局部性和平移不变性,原本需要 $H \times W \times H \times W$ 个参数的全连接层,直接锐减到只需要 $(2\Delta + 1) \times (2\Delta + 1)$ 个参数(即一个很小的卷积核的大小,如 $3 \times 3 = 9$ 个参数)。
全连接层: 全局感知,位置敏感,参数极多。
卷积层: 局部感知,位置共享,参数极少。
四个核心概念:卷积核、步长、填充和多通道处理。
卷积层是 CNN 的基础特征提取器,其核心逻辑是利用**卷积核(Kernel)**在输入数据上进行滑动扫描,通过局部区域的“逐元素相乘再求和”来提取空间特征(如边缘、纹理)。
其运作受三大超参数控制:
卷积核大小(Filter Size): 决定了每次提取特征的局部感受野大小(常为 3x3 或 5x5)。
步长(Stride): 卷积核滑动的步幅,决定了扫描的密度以及特征图的降采样程度。
填充(Padding): 在输入数据边缘补零,用于保留边界信息并灵活控制输出尺寸。(**为1输入输出一样)
核心公式: 输出尺寸 $W_{out} = \lfloor (W_{in} - F + 2P) / S \rfloor + 1$。—-每一层
多通道逻辑: 卷积核的深度必须与输入数据的通道数一致(如 RGB 的 3 通道);而当前层使用的卷积核的“总个数”,则决定了下一层输出特征图的通道数。
每个通道的卷积核不一样,但同一层不同通道的卷积核大小尽量一样
多输入层(Multiple Input Channels)
真实的数据往往有厚度(通道数 $C_{in}$)。比如一张 RGB 图片,它的形状是 [3, Height, Width],输入通道数为 3。
运作机制: 面对多通道输入,单个“滤波器(Filter)”不再是一个简单的二维矩阵,而是一个三维张量。它的深度必须与输入通道数严格对齐。在进行一次卷积运算时,滤波器在每个通道上分别进行二维卷积,然后将所有通道的计算结果相加,最终输出一个单通道的二维平面。
通俗理解: 就像做菜,红、绿、蓝三个通道分别是盐、糖、醋,一个滤波器就是一张特定的配方,它把三种调料按照特定比例混合在一起,产生一种全新的味道(单通道输出)。
多输出层(Multiple Output Channels)
如果只用一个滤波器,我们只能提取一种特征(比如只提取垂直边缘)。为了捕捉图像中丰富多样的特征(纹理、形状、色彩对比等),我们需要使用多组不同的滤波器。
运作机制: 我们定义 $C_{out}$ 个独立的滤波器。每个滤波器独立对多通道输入进行扫描和相加操作,各自生成一个单通道的二维输出。最后,将这 $C_{out}$ 个二维输出在通道维度上堆叠起来,就得到了具有多个输出通道的特征图。
总结:输入通道决定了单个滤波器的“厚度”,输出通道决定了滤波器的“总个数”。
空间降维神器:1x1 卷积层—-全连接层/卷积层
1x1 卷积($K=1$)是卷积神经网络中极其巧妙的设计,最早在 Network in Network (NiN) 中提出,并在 ResNet 和 Inception 网络中发扬光大。
既然它的感受野只有 1x1,意味着它完全不提取相邻像素的空间结构特征,那它有什么用?
跨通道的信息交互(通道融合): 它虽然在空间上是 1x1,但在通道维度上,它依然会遍历所有输入通道并求和。它本质上是对不同通道的同一空间位置上的像素进行了一次线性组合(全连接)。
灵活的降维与升维(控制计算量): 通过设置 1x1 卷积的输出通道数,我们可以随意增加或减少特征图的通道数。例如,将 256 通道的特征图通过 64 个 1x1 卷积核,输出就变成了 64 通道,极大地压缩了后续层的计算负担。
维度的自由伸缩(降维/升维): 通过控制输出通道数,构建“瓶颈层(Bottleneck)”,在进行高昂的 $3 \times 3$ 空间卷积前大幅降低通道厚度,将模型计算量和参数量呈几何级数缩减。
增加非线性: 1x1 卷积后通常会紧跟 ReLU 激活函数,在不改变特征图物理尺寸的前提下,增加了网络的非线性表达能力。
计算复杂度
对于一个标准的卷积层(输入通道 $C_{in}$,输出通道 $C_{out}$,卷积核边长 $K$,输出特征图宽 $W_{out}$ 高 $H_{out}$),其复杂度如下:
1. 空间复杂度(参数量 Parameters)
参数量决定了模型占用显存的大小以及极易过拟合的程度。单个滤波器的参数量是 $C_{in} \times K^2$。我们有 $C_{out}$ 个滤波器。
$$\text{Params} = C_{in} \times K^2 \times C_{out}$$
(注:如果加上偏置 bias,则为 $(C{in} \times K^2 + 1) \times C_{out}$)_
2. 时间复杂度(计算量 FLOPs / MACs)
计算量决定了模型推理的速度。对于输出特征图上的每一个像素,都需要进行一次完整的“乘加运算”。一次点积包含 $C_{in} \times K^2$ 次乘法操作。整个输出特征图有 $H_{out} \times W_{out}$ 个像素,且共有 $C_{out}$ 个通道。
总的乘加运算次数(MACs)为:
$$\text{MACs} = H_{out} \times W_{out} \times C_{out} \times C_{in} \times K^2$$
(注:由于一次乘法加一次加法通常算作 2 次浮点运算 FLOPs,因此 $\text{FLOPs} \approx 2 \times \text{MACs}$)
复杂度启示: 从公式可以看出,计算量与输入通道 $C_{in}$ 和输出通道 $C_{out}$ 均成正比。这也是为什么在进行昂贵的 3x3 卷积前,常使用 1x1 卷积先降低 $C_{in}$(如上面代码所示的“瓶颈”结构),这能成倍地削减总体的计算复杂度。
池化
使对位置信息不那么敏感
池化层的操作与卷积层非常相似,也是使用一个“滑动窗口”(往往是 $2 \times 2$ 或 $3 \times 3$ 的尺寸)在输入特征图上按一定的步长(Stride)滑动。
但池化层与卷积层有两个本质的区别:
没有可学习的参数: 卷积核里装的是需要通过反向传播学习的权重(Weights),而池化窗口仅仅是一个“预设的计算规则”(比如求最大值或求平均值),不需要被训练。
按通道独立进行: 卷积操作会将所有通道的信息融合在一起,而池化操作对特征图的每一个通道是独立处理的。因此,池化通常不会改变特征图的通道数(输入是 64 通道,输出依然是 64 通道)。
池化层输出尺寸的计算公式与卷积层完全一致:
$$W_{out} = \lfloor \frac{W_{in} - F + 2P}{S} \rfloor + 1$$
(注:绝大多数情况下,池化层不使用填充,即 $P=0$。最经典的设置是窗口大小 $F=2$,步长 $S=2$,这会让特征图的长宽直接减半。)
最大池化层(Max Pooling)
工作原理: 在滑动窗口覆盖的局部区域内,直接选出数值最大的那一个像素作为输出,丢弃其他所有像素。
物理直觉: 在特征图中,数值越大,代表该位置对某种特征(如边缘、特定纹理)的响应越强烈。最大池化就是一种“优中选优”的策略,它只保留局部区域内最显著、最强烈的特征,过滤掉微弱的背景噪音。
优势: 1. 能很好地保留图像的纹理和边缘信息。
- 提供了极强的局部平移不变性。假设特征在图像中平移了 1 个像素,只要它依然落在同一个 $2 \times 2$ 的池化窗口内,池化后的输出结果就完全不变。
平均池化层(Average Pooling)
工作原理: 在滑动窗口覆盖的局部区域内,计算所有像素的算术平均值作为输出。
物理直觉: 平均池化会将局部区域内的所有信息进行融合和平滑处理。它不再寻找“最强”特征,而是强调整体情况。
应用场景的变迁: 在早期的经典网络(如 LeNet)中,平均池化常用于下采样。但在现代网络中,由于它容易导致特征“模糊化”(把强特征和弱特征中和了),在提取空间局部特征时,最大池化已经基本上取代了平均池化。
全局平均池化(Global Average Pooling, GAP)的崛起: 如今,平均池化最常用的形态是“全局”平均池化。在网络的最后端(分类输出前),不再使用容易导致参数爆炸的全连接层,而是将整个特征图(不管多大)直接求平均,压缩成一个单点数值。这极大降低了过拟合风险,是 ResNet 等现代网络的标准配置。
与卷积的顺序
在卷积神经网络的设计范式中,池化层(Pooling)严格放置于卷积层(Conv)和激活函数(通常为 ReLU)的后面。
核心原因与分工:
先提取,后浓缩: 卷积层需要高分辨率的输入以确保不遗漏微小的局部特征;待特征响应图生成后,再由池化层进行空间降维,滤除对位置过度敏感的冗余信息,保留最强烈的特征信号。
经典的模块化结构: 现代 CNN 通常由多个重复的
Conv -> ReLU -> Pool基础模块串联而成。这种组合使得特征图在网络前向传播的过程中,呈现出“空间尺寸不断缩小(由池化主导),特征通道数不断增加(由卷积主导)”的规律,最终将底层的像素信息转化为高层抽象的语义特征。
LeNet
LeNet(准确地说是 LeNet-5)是卷积神经网络(CNN)的“开山鼻祖”。它由深度学习先驱 Yann LeCun 于 1998 年提出,最初被设计用于识别美国邮政信封上的手写数字(MNIST 数据集)以及银行支票上的数字。
LeNet-5 (2卷积+池化+2全连接)最伟大的贡献在于,它首次确立了现代卷积神经网络的标准架构范式:卷积层提取特征 $\rightarrow$ 池化层降维 $\rightarrow$ 全连接层输出分类。
架构范式: 确立了现代 CNN 的标准工作流。整个网络呈“漏斗状”,通过交替堆叠卷积层和池化层,使得空间分辨率逐层降低(提取平移不变性),而特征通道数逐层增加(提取更丰富的语义语义),最终通过全连接层将抽象特征映射为分类概率。
AlexNet
输入图像 → 卷积 + ReLU + 池化 → 卷积 + ReLU + 池化 → 多层卷积 → 池化 → 两层大规模全连接 → Softmax 分类
更具体一点:
Conv1: 96 个 11×11
Conv2: 256 个 5×5
Conv3: 384 个 3×3
Conv4: 384 个 3×3
Conv5: 256 个 3×3
FC6: 4096
FC7: 4096
FC8: 1000
首次使用 ReLU 激活函数: 彻底抛弃了 LeNet 时代的 Sigmoid/Tanh。ReLU($f(x) = \max(0, x)$)计算极快,且在正区间梯度恒为 1,完美解决了深层网络中的梯度消失问题。
引入 Dropout 正则化: 包含千万级参数的全连接层极易过拟合。AlexNet 首次使用 Dropout,在训练时随机让一部分神经元“失活”(输出置 0),强迫网络不依赖某些局部特征,从而极大提升了泛化能力。
重叠最大池化(Overlapping Max Pooling): LeNet 中的池化窗口和步长是相等的(如窗口 2,步长 2),没有重叠。AlexNet 使用 $3 \times 3$ 的窗口,步长设为 2。这种带重叠的池化不仅能降维,还能进一步缓解过拟合。
数据增强(Data Augmentation): 通过对图像进行随机裁剪、翻转和颜色变换,人为地扩充了训练集,让模型见识到了更多变异的数据。
VGG
用多个极小的 $3 \times 3$ 卷积核串联,效果完爆单个大卷积核。
这是为什么?结合网络结构,有两个核心优势:
相同的感受野,更少的参数: 两个 $3 \times 3$ 卷积层串联,其感受野等价于一个 $5 \times 5$ 的卷积层;三个串联等价于一个 $7 \times 7$。
我们算一笔账(假设输入输出通道数都是 $C$):
一个 $7 \times 7$ 卷积的参数量:$7 \times 7 \times C \times C = 49C^2$
三个 $3 \times 3$ 卷积的参数量:$3 \times (3 \times 3 \times C \times C) = 27C^2$
结论: 堆叠小卷积核不仅视野没变小,参数量反而大幅下降。
更强的非线性表达: 一个 $7 \times 7$ 卷积只能跟一个 ReLU 激活函数;而三个 $3 \times 3$ 卷积中间可以穿插三次 ReLU。网络变得更“深”,非线性拟合能力极大增强。
通常由两部分组成:
前半部分:卷积特征提取
由多个卷积块组成,每个卷积块一般包含:
- 若干个 3×3 卷积层
- ReLU 激活
- 一个 2×2 最大池化层(stride=2)
后半部分:分类器
通常是: - 3 个全连接层
- 最后接 softmax 输出分类结果
VGG-16 的“16”是指有可学习参数的层数:
- 13 个卷积层
- 3 个全连接层
总共: - 16 层
而池化层、ReLU 层通常不计入这个数字。
VGG 是一种经典的深层卷积神经网络,其核心思想是使用多个连续的 3×3 小卷积核来替代大卷积核,并通过不断堆叠卷积层提升模型的表达能力。以 VGG-16 为代表,它通常由 5 个卷积块和 3 个全连接层组成,具有结构统一、层次清晰、易于理解的特点。
VGG 证明了加深网络深度能够显著提升图像分类性能,但也存在参数量大、计算开销高的问题。它在卷积神经网络发展史上具有重要地位,并对后续的 ResNet 等模型产生了深远影响。
NIN(network in network)
全连接层—–会让学习参数变多
MLPConv(微型网络卷积) 与 GAP(全局平均池化)。
MLPConv (取代传统线性卷积)
传统卷积的痛点: 传统的卷积核仅仅是在进行简单的“线性内积”运算(哪怕后面跟了 ReLU,单层的表达能力依然有限)。对于高度非线性的复杂图像特征,传统卷积往往力不从心,只能靠盲目增加通道数来弥补。
NIN 的解决方案:网络中的网络 (Network in Network)
既然单层线性卷积不够强,那就在每次提取局部特征时,塞进去一个微型神经网络(MLP,多层感知机)。
理论上的 MLPConv: 在滑动窗口提取特征时,不使用简单的线性矩阵相乘,而是用一个包含隐藏层的微型多层神经网络来处理这个局部斑块。
代码上的绝妙实现 ($1 \times 1$ 卷积): 在物理实现上,对每个像素点进行全连接的多层感知机运算,在数学上严格等价于串联多个 $1 \times 1$ 的卷积层!NIN 首次将 $1 \times 1$ 卷积作为核心组件引入网络,通过“标准卷积 + 两个 $1 \times 1$ 卷积”的组合,极大增强了局部的非线性拟合能力。
1 | import torch |
全局平均池化 GAP (消灭全连接层)
传统全连接层的痛点: 回顾我们之前讲的 AlexNet 和 VGG,网络最后都跟着极其庞大的全连接层(FC layer)。VGG 甚至有 80% 的参数集中在第一个全连接层里。这不仅导致模型极其臃肿,而且全连接层完全破坏了图像的空间结构,极易导致严重的过拟合(Overfitting),必须依赖 Dropout 来强行续命。
NIN 的解决方案:全局平均池化 (Global Average Pooling, GAP) NIN 大胆地提出了一个近乎极端的想法:彻底砍掉网络末端的所有全连接层!
运作机制: 假设我们要进行 10分类 任务。NIN 会在最后一个卷积层输出正好 10个通道 的特征图。然后,对这 10 张特征图分别进行“求平均”操作。一张图得出一个数值,10张图就得出 10 个数值,这 10 个数值直接送入 Softmax 计算分类概率。
优势: 1. 参数量暴降为 0: GAP 操作没有任何需要学习的参数(全连接层动辄上亿参数),模型体积直接缩小了数十倍。 2. 自带防过拟合属性: 没有了海量参数的死记硬背,GAP 强制特征图与类别直接建立物理联系(每一张特征图代表一个类别的置信度分布),大大提升了模型的泛化能力。 3. 支持任意输入尺寸: 全连接层要求输入尺寸必须固定;而 GAP 无论输入多大,最终都能平均成单个数值,使得网络可以接受任意尺寸的图片。
GoogLeNet
Inception 模块(“小孩子才做选择,我全都要”)
GoogLeNet 的破局思路: 既然不知道哪个最好,那我们就在同一层把它们全部用上,然后把结果拼接在一起,让网络自己去学习应该多依赖哪部分特征。
一个标准的 Inception 模块由 **4 条并行的分支(Branch)**组成:
分支 1: 单一的 $1 \times 1$ 卷积(提取像素级特征,跨通道融合)。
分支 2: $1 \times 1$ 卷积(降维) $\rightarrow$ $3 \times 3$ 卷积(提取中等局部特征)。
分支 3: $1 \times 1$ 卷积(降维) $\rightarrow$ $5 \times 5$ 卷积(提取较大感受野的全局特征)。
分支 4: $3 \times 3$ 最大池化(提取显著空间特征) $\rightarrow$ $1 \times 1$ 卷积(降维)。
这四条分支处理完相同的输入后,会输出长宽完全一致的特征图。最后,通过一个 Concat(拼接)操作,在通道维度上将它们像三明治一样叠起来。
三大核心架构创新:
Inception 模块(多尺度并行): 在同一层内并行使用 $1 \times 1$、$3 \times 3$、$5 \times 5$ 卷积和 $3 \times 3$ 最大池化,在不同尺度上同时提取局部、中等和全局感受野的特征,最后在通道维度拼接(Concat),实现了网络的“变宽”。
瓶颈结构($1 \times 1$ 卷积降维): 在进行昂贵的 $3 \times 3$ 和 $5 \times 5$ 卷积之前,强制使用 $1 \times 1$ 卷积压缩通道数,这是防止 Inception 模块计算量爆炸的关键阀门。
辅助分类器(应对梯度消失): 在网络的中低层接入额外的分类器进行辅助训练,强行注入回传梯度,保证深层网络早期的权重能得到有效更新(仅在训练期生效)。
批量归一化(Batch Normalization,简称 BN)
内部协变量偏移: 由于网络是由多层串联而成的,在训练过程中,随着浅层权重的不断更新,传递给深层的数据分布(均值和方差)会发生剧烈变化。深层网络被迫不断适应这种变化,导致训练速度极慢,且极其容易陷入激活函数的饱和区(即梯度消失)。
BN 的核心思想非常霸道:既然你的数据分布老是变,那我就在每一层把数据强行“按”回一个标准的正态分布!
具体操作分为四步(假设我们对当前小批量 Batch 内的 $m$ 个数据点进行处理):
求均值(Mean): 计算这批数据的平均值 $\mu_B$。
$$\mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i$$
求方差(Variance): 计算这批数据的方差 $\sigma_B^2$。
$$\sigma_B^2 = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2$$
标准化(Normalize): 让当前数据减去均值,除以标准差(加上微小常数 $\epsilon$ 防止分母为 0)。此时,数据被强行拉成均值为 0、方差为 1 的标准分布。
$$\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}$$
缩放与平移(Scale and Shift,极其关键的一步): 如果只是强行把数据变成均值为 0、方差为 1,可能会破坏网络本来辛辛苦苦学到的特征表达能力(比如强行把数据塞进了激活函数的线性区)。
因此,BN 引入了两个可学习的参数:缩放因子 $\gamma$ (Gamma) 和平移因子 $\beta$ (Beta)。
$$y_i = \gamma \hat{x}_i + \beta$$
网络会自己通过反向传播学习出最优的 $\gamma$ 和 $\beta$。 如果网络发现“均值为 0、方差为 1”不好,它可以自动把 $\gamma$ 和 $\beta$ 调回原来的方差和均值,实现了进退自如。
在训练阶段(
model.train()): BN 计算的是**当前正在处理的这一个小批量(Mini-batch)数据的均值和方差。同时,它会在后台默默用滑动平均(Exponential Moving Average, EMA)**的方式,记录下全局的均值和方差。在测试/推理阶段(
model.eval()): 测试时,我们可能一次只输入一张图片,根本没有“批量”可言,算不出 Batch 的均值和方差。此时,BN 会**自动停止计算均值和方差,而是直接调取训练时记录下的“全局滑动平均均值和方差”**来进行归一化。
优点 : 模型更稳定(可以使用更大的学习率 )—-收敛变快
ResNet
在引入批量归一化(BN)之后,梯度消失/爆炸问题已经得到了极大缓解。人们理所当然地认为:网络越深,特征提取能力越强,准确率应该越高。
如果我们简单粗暴地将层数往上堆叠,当网络达到 56 层时,它的训练误差和测试误差竟然都比 20 层的网络还要高!
这不是过拟合(因为训练误差也很高),这被称为网络退化问题。
原因何在?
假设 20 层的网络已经达到了最优解,那么后面多加的 36 层,理论上只需要做一个“什么都不做”的恒等映射(Identity Mapping,即输出等于输入),56 层的性能至少应该和 20 层一样好。
但事实证明,让一堆非线性的卷积层去学习 $H(x) = x$(什么都不做)是非常困难的,优化器很容易把权重带偏,导致性能断崖式下跌。
**残差块(Residual Block)与跳跃连接(Skip Connection)
既然让网络学习恒等映射 $H(x) = x$ 这么难,何恺明提出:不如我们直接在网络结构里把 $x$ 加过去!
假设某个网络模块预期的真实映射函数为 $H(x)$。
ResNet 不让中间的卷积层直接去拟合 $H(x)$,而是让它们去拟合输入与输出之间的**“残差(Residual)”,即 $F(x) = H(x) - x$。 最终的输出变为:$H(x) = F(x) + x$**。
在物理结构上,这就体现为一条跳跃连接(Skip Connection / Shortcut),直接将输入 $x$ 绕过几层卷积,与卷积的输出 $F(x)$ 相加。
为什么这个简单的“加法”如此有效?
天然的恒等映射: 如果网络发现当前层已经不需要提取新特征了,它只需要通过权重衰减让卷积层学到的 $F(x)$ 逼近于 0,那么输出自然就变成了 $H(x) = 0 + x = x$。这极其容易优化。
拯救梯度反向传播: 在反向传播时,根据加法的求导法则,梯度可以通过旁路(Shortcut)无损地直接传回前层,彻底杜绝了深层网络梯度衰减的问题。
CPU与GPU
1. CPU (中央处理器):博学的“大学教授”
设计哲学: 优化极低的响应延迟和极强的复杂**逻辑控制能力。
架构特点: 核心数量少(通常 4 到 64 核),但每个核心极其强悍。它拥有极高的主频,庞大的缓存(Cache)用于减少内存访问延迟,以及极其复杂的控制单元(支持乱序执行、分支预测等)。
擅长领域: 串行计算、复杂的逻辑分支判断(If-Else)、操作系统调度、数据库查询等交互性强、不可预测的任务。
如何提高 CPU 的利用率?——-读写效率与多线程
1. 榨干多核性能:多线程与多进程 这是最直接的手段。现代 CPU 都有多核,如果你的代码是单线程的,利用率永远突破不了一个核心的上限(例如 8 核 CPU 最多只有 12.5% 利用率)。
- 优化方案: 在计算密集型任务中,使用多进程(如 Python 的
multiprocessing模块绕过 GIL)将任务分发到所有物理核心。
2. 消除 I/O 瓶颈:异步编程 当程序需要读写磁盘、请求网络资源或查询数据库时,CPU 会处于闲置等待状态。
- 优化方案: 使用异步 I/O(如 Python 的
asyncio或 Node.js)或者多线程。当遇到网络请求时,CPU 立即切走去干别的活,等数据返回了再切回来,从而把 CPU 的等待时间全部填满。
3. 数据结构与缓存命中率(Cache Locality) CPU 访问内存的速度远慢于访问自身的 L1/L2 缓存。如果数据在内存中是连续分布(按行存储)的,CPU 会一次性将相邻数据加载进缓存,极大提升处理速度。避免频繁的链表跳转,多使用连续数组。
2. GPU (图形处理器):庞大的“流水线工人”
设计哲学: 优化极高的**吞吐量和并发处理能力。
架构特点: 核心数量极多(成千上万个流处理器),但每个核心的结构非常简单,主频较低。缓存极小,控制单元也非常简陋,几乎没有分支预测能力。
擅长领域: 大规模并行计算、矩阵运算、图像渲染、深度学习训练。在这些任务中,成千上万个数据需要执行完全相同的计算(单指令多数据流,SIMD)。
C——Computer—计算 G—Graph—-图形渲染
如何提高 GPU 的利用率?
**保证数据以极快的速度、极大的量级源源不断地喂给显存。
1. 提升 Batch Size(批处理大小) GPU 拥有成千上万个核心,如果每次只给它几张图片,它连“热身”都算不上。
- 优化方案: 在显存(VRAM)允许的范围内,尽可能增大 Batch Size。显存占满,通常意味着 GPU 核心有足够多的并发任务去计算。
2. 打通数据加载的“任督二脉”(消除 CPU 瓶颈) 这是最常见的 GPU 闲置原因:CPU 预处理数据的速度太慢,跟不上 GPU 的计算速度。 GPU 算完了一个 Batch,必须停下来等 CPU 读硬盘、做图像裁剪和增强。
优化方案: 开启多进程数据加载,并将内存锁定在页锁定内存(Pinned Memory),加速 CPU 到 GPU 的数据传输。
代码结合示范(以 PyTorch 为例):
Python
1
2
3
4
5
6
7
8
9
10
11
12
13from torch.utils.data import DataLoader
# 错误示范:单进程加载,数据都在虚拟内存里缓慢交换,导致 GPU 频繁发呆
# dataloader = DataLoader(dataset, batch_size=256)
# 正确示范:开启多线程预加载,锁定内存加速传输
dataloader = DataLoader(
dataset,
batch_size=256,
num_workers=8, # 开启 8 个 CPU 进程专门负责读数据和增强
pin_memory=True, # 将数据锁在物理内存,加速向 GPU 显存的 PCIe 传输
prefetch_factor=2 # 提前预取后续的 Batch
)
3. 启用混合精度训练(Mixed Precision) 传统的计算使用 32 位浮点数(FP32)。现代 GPU(特别是带有 Tensor Core 的 NVIDIA 显卡)针对 16 位浮点数(FP16/BF16)有极其恐怖的硬件加速加成。
- 优化方案: 使用自动混合精度(AMP)。这不仅能将显存占用减半(允许更大的 Batch Size),还能直接让计算吞吐量翻倍。
硬件比较
1. CPU (Central Processing Unit) - 绝对的通用霸主
核心特性: 极强的控制逻辑、分支预测和庞大的缓存(Cache)。冯·诺依曼架构的极致体现。
优势: 灵活性拉满。什么代码都能跑(操作系统、数据库、AI 调度)。开发极其容易(C++, Python, Java 随便写)。
劣势: 算力密度极低。芯片上绝大部分面积被控制单元和缓存占用了,真正用来做数学计算的 ALU(算术逻辑单元)非常少,极度不擅长海量并行计算。
2. GPU (Graphics Processing Unit) - 并行算力怪兽
核心特性: 极简的控制逻辑,极小的缓存,把省下来的芯片面积全部塞满了计算核心(ALU)。单指令多数据流(SIMD)。
优势: 吞吐量无敌。擅长处理高度统一的并行计算(如图形渲染、深度学习的矩阵乘法)。
劣势: 无法独立工作,必须由 CPU 当“包工头”来派发任务。功耗极大,遇到复杂的
If-Else逻辑分支时性能会暴跌。
3. DSP (Digital Signal Processor) - 算法特种兵
核心特性: 针对特定的数学运算(尤其是乘加运算 MAC 和快速傅里叶变换 FFT)在硬件底层做了极其特殊的电路设计(哈佛架构,指令和数据分开存储)。
优势: 处理音频、视频、雷达、通信信号时效率极高,且功耗很低。
劣势: 编程模型特殊,生态小众,通用计算能力很差,正在被现代 CPU(加入了类似 AVX 矢量指令集)和轻量级 NPU 逐渐边缘化。
4. FPGA (Field Programmable Gate Array) - 硬件变形金刚
核心特性: 它出厂时是一张“白纸”,上面布满了未连接的逻辑门(查找表 LUT、寄存器)。开发者需要用硬件描述语言(Verilog / VHDL)去“烧录”它,物理连线会被重新配置,硬生生把算法变成了物理电路。
优势:
真正的极低时延: 因为是纯物理电路直连,没有 CPU/GPU 那种读取指令、解码的开销,纳秒级响应(在金融高频交易、导弹控制中是王牌)。
能效比极高: 只耗费必要的逻辑门。
劣势: 开发难度处于地狱级别。找一个能写出高效 FPGA 代码的硬件工程师极其昂贵且困难;且单片成本较高。
5. ASIC (Application-Specific Integrated Circuit) - 终极定制武器
核心特性: 为单一特定目标完全定制的“死硬件”。比如谷歌的 TPU(专门搞张量运算)、比特币矿机芯片、手机里的 NPU。
优势: 在它被设计出来的特定任务上,它的性能最高、体积最小、功耗最低(能效比无敌)。
劣势: 毫无灵活性(一旦流片,哪怕算法改了一个符号,这块芯片就成了废硅)。此外,研发成本极其高昂(流片一次动辄几百万到上千万美元),如果没有海量出货量来分摊成本,根本玩不起。
TPU(张量处理单元,Tensor Processing Unit)
TPU 本质上就是 Google 为深度学习量身定制的顶级 ASIC。
由于深度学习(无论是早期的 AlphaGo,还是现在的 Transformer / 大语言模型)底层 90% 以上的计算都是矩阵乘法(Matrix Multiplication),Google 意识到:既然我们只做矩阵乘法,为什么还要忍受 CPU 和 GPU 那些为了“通用性”而设计的冗余结构呢?
于是,TPU 诞生了。它抛弃了图形渲染能力,抛弃了复杂的浮点运算标准,将所有的晶体管全部砸向了深度学习的核心命门。
一、 核心魔法:脉动阵列(Systolic Array)
这是 TPU 区别于 CPU 和 GPU 最本质的物理架构创新。
传统 CPU/GPU 的痛点(冯·诺依曼瓶颈): 每次进行乘法和加法运算时,计算核心(ALU)都需要从寄存器或缓存(SRAM)中读取数据,算完后再把结果写回内存。**“读取-计算-写入”**这个过程中,读写数据的延迟和功耗,远大于计算本身。
TPU 的解决之道(脉动阵列): 想象一下心脏泵血(Systolic 在医学上就是“心脏收缩”的意思)。TPU 在芯片上硬连了一个庞大的乘加单元(MAC)矩阵(比如 $256 \times 256$)。数据只要从内存中取出来一次,就会像水流一样,在这个阵列中直接从上一个计算单元流向下一个计算单元,一边流动一边累加结果,直到流出阵列才写回内存。
二、 极端的精度取舍:BF16 与 INT8 量化
深度学习的一个神奇之处在于:它不需要绝对精确的数学计算,它只需要知道大概的趋势(概率)。
GPU 的历史包袱: 早期的 GPU 主要用于科学计算和游戏图形,严格遵守 IEEE 的 32 位(FP32)或 64 位(FP64)浮点数标准,极其占用晶体管和显存带宽。
TPU 的暴力阉割: Google 在设计 TPU 时,直接在硬件底层大规模支持 **8 位整数(INT8)**进行推理,以及自己发明的 bfloat16(BF16) 格式进行训练。BF16 砍掉了表示精度的尾数位,保留了表示范围的指数位。这意味着 TPU 可以用一半的显存带宽、极低的功耗,完成和 GPU 几乎一样的 AI 训练效果。
三、 无敌的互联架构:TPU Pod
当大模型(如拥有千亿参数的模型)出现后,单块芯片的算力已经毫无意义,拼的是集群网络。
GPU 集群通常需要昂贵的外部交换机(如 NVIDIA 的 NVSwitch 和 InfiniBand 网络)来让成千上万张显卡互相通信,网络拓扑极其复杂。
TPU 在设计之初,就在芯片内部集成了超高带宽的专用互联网络接口(ICI)。几千块 TPU 可以像拼图一样,通过极其简单的 2D 或 3D 环面拓扑(Torus)直接连在一起,组成一台超级计算机(TPU Pod)。这种原生互联让 TPU 在训练超大规模模型时,具有极高的线性加速比(即增加机器不会因为通信延迟而导致算力损耗)。
| 维度 | NVIDIA GPU | Google TPU |
|---|---|---|
| 定位 | 高度通用的并行计算王牌 | 专为深度学习定制的终极杀器 (ASIC) |
| 核心架构 | 海量流处理器,基于 SIMT(单指令多线程) | 脉动阵列(Systolic Array),专攻张量矩阵乘法 |
| 生态与灵活性 | 绝对统治地位。 CUDA 生态坚不可摧,无论写什么古怪的自定义代码都能跑。可以买回家插在自己电脑上。 | 深度绑定。 对 TensorFlow 和 JAX 支持极好(PyTorch支持也在完善)。不单独卖芯片,只能在 Google Cloud 上租用。 |
| 极致性能表现 | 遇到包含大量非标准操作、复杂分支、或者小 Batch Size 的任务时表现极佳。 | 在结构标准的大模型(如 Transformer)、超大 Batch Size 训练时,能效比和算力吞吐量通常优于同代 GPU。 |
单机多卡并行(Single-Machine Multi-GPU Parallelism)
有的是切分数据,有的是切分模型。
一、 数据并行(Data Parallelism, DP/DDP):最基础、最常用
适用场景: 模型不算太大(单张显卡能完全装下),但训练数据量极大,想加速训练。
核心思想:“同样的模型,不同的数据,最后对口供”。
模型复制: 首先,把一模一样的完整神经网络模型,复制到每一张 GPU 上。如果你的机器有 4 张卡,这 4 张卡里装的是完全相同的模型副本。
数据切分: 将一个巨大的 Data Batch(比如 1024 张图片)切分成 4 份(每张卡分到 256 张图片)。
独立前向与反向传播: 4 张卡同时开始计算自己手里那份数据的 Loss,并算出自己那份数据的梯度(Gradient)。
梯度聚合(All-Reduce 操作,最核心的一步): 在更新权重之前,4 张卡必须停下来“开个会”。它们互相交换自己算出的梯度,然后求出一个平均梯度。
同步更新: 所有卡使用这个平均梯度来更新自己的权重。这样就保证了在下一轮计算开始时,4 张卡里的模型依然是完全一模一样的。
技术演进: 早期 PyTorch 使用
DataParallel (DP),它存在单进程多线程的 GIL 锁问题,且主卡负责分发数据,负载极不均衡。现在工业界绝对的标准是DistributedDataParallel (DDP),它采用多进程架构,每张卡独立运行,通信效率极高。优缺点 :batch_size调大(需要收敛时间变多),学习率调大(验证集损失跳),有可能精度变低(理论精度不变,但需要更大的epoch,所以需要考虑并行所花时间与非并行所花时间)
二、 流水线并行(Pipeline Parallelism, PP):接力赛跑
适用场景: 模型太大,单张卡的显存装不下完整的模型。
核心思想:“按网络层级切分,像工厂流水线一样接力计算”。
假设我们有一个 40 层的模型,但单卡最多只能装下 10 层。
模型纵向切分: 把第 1-10 层放在 GPU 0,11-20 层放在 GPU 1,21-30 层放在 GPU 2,31-40 层放在 GPU 3。
前向传播接力: 数据首先进入 GPU 0 计算。GPU 0 算完后,把中间结果(Activations)通过 PCIe 总线传给 GPU 1;GPU 1 接着算,再传给 GPU 2……直到最后 GPU 3 算出最终的 Loss。
反向传播接力: 计算梯度时也是倒着来,GPU 3 先算,把误差梯度传给 GPU 2,一路倒推回 GPU 0。
- 致命痛点(流水线气泡 Pipeline Bubble): 当 GPU 0 在算的时候,GPU 1、2、3 都在干等(Idle)。为了解决这个问题,通常会把数据切成极其微小的数据块(Micro-batches),让流水线尽量跑满,但依然无法彻底消除空窗期。
三、 张量并行(Tensor Parallelism, TP):显微镜下的手术
适用场景: 模型巨大(如超大语言模型 Transformer),且极度追求单层计算效率,通常配合 NVLink 等超高速硬件互联使用。
核心思想:“把矩阵乘法拆开,让多张卡一起算同一层网络”。
这比流水线并行要微观得多。著名的 Megatron-LM 框架就是把这招用到了极致。
假设网络中有一层巨大的线性层(全连接层)进行矩阵乘法 $Y = X \times W$。
权重切块: 如果权重矩阵 $W$ 太大,我们直接把 $W$ 竖着切成两半,GPU 0 拿左半边 $W_1$,GPU 1 拿右半边 $W_2$。
分头计算: 给两张卡输入同样的数据 $X$,GPU 0 算出结果的左半边 $Y_1$,GPU 1 算出右半边 $Y_2$。
瞬间拼接: 在进入下一层网络之前,两张卡迅速通过极其高速的通信链路(如 NVIDIA 的 NVLink,速度远超普通主板 PCIe),将 $Y_1$ 和 $Y_2$ 拼接成完整的 $Y$。
- 优缺点: 完全没有流水线气泡,显存分配极其均匀。但通信极其频繁且庞大,每次矩阵乘法后都要通信一次。因此张量并行几乎只能局限于单机内部(利用 NVLink),无法跨机器使用。
在单机内部,利用 NVLink 进行极速的张量并行 (TP);跨越多台机器时,使用流水线并行 (PP)切分超大模型;最后在整个超算集群层面,套上一层数据并行(DP) 来消化海量的训练数据。
并行性能
“一个程序的并行加速极限,受限于它不能被并行化的那一部分(串行部分)。”
在并行计算(尤其是多卡训练深度学习模型)中,我们最容易陷入一个直觉陷阱:“我用了 4 张显卡,训练速度就应该提升 4 倍。”
但现实往往是非常残酷的:1 + 1 几乎永远小于 2。有时加了更多的显卡,速度不仅没有成倍提升,甚至还可能变慢。
加速比 (Speedup, $S$)
定义: 单卡训练所需时间 $T_1$ 与 $N$ 张卡训练所需时间 $T_N$ 的比值。公式为 $S = T_1 / T_N$。
理想状态: 线性加速(Linear Speedup),即用了 4 张卡,速度就快 4 倍($S = 4$)。
并行效率 (Efficiency, $E$)
定义: 加速比除以显卡数量。公式为 $E = S / N$。
物理意义: 衡量你的显卡有多“卖力”。如果 4 张卡的加速比是 3.2 倍,那么效率就是 $3.2 / 4 = 80%$。这意味着有 20% 的算力被无谓地消耗掉了。
性能损耗:
通信开销 (Communication Overhead): 这是最大的性能窃贼。多张卡在计算完各自的部分后,必须停下来互相交换数据(例如交换梯度或特征图)。如果计算花去了 80 毫秒,但互相传输数据却花了 20 毫秒,那么你的显卡在传输期间其实是在“发呆”。
同步等待 (Synchronization Barrier / 木桶效应): 在数据并行中,所有卡必须等最慢的那张卡算完,才能汇总梯度。如果某张卡因为散热不好降频了,或者分配到的数据恰好稍微复杂一点点,其他所有极速狂奔的卡都得停下来等它。
串行部分 (Serial Portion): 并不是所有任务都能被拆分。比如数据加载前的预处理、模型保存到硬盘、或者最后汇总损失函数的那个步骤,往往只能由单个 CPU 或主卡单线程完成。
并行问题
1. “Batch Size 调大(需要收敛时间变多)”
现象本质: 这里说的“收敛时间变多”,指的是达到相同收敛标准所需要的迭代轮数(Epochs)增加了。
物理直觉: 假设原本 Batch Size 是 32,模型每看 32 张图片就更新一次权重(走一步);现在 4 卡并行,全局 Batch Size 变成 128,模型看了 128 张图片才更新一次权重。虽然单步计算因为并行变快了,但在过完同一个 Epoch 的数据量时,模型更新权重的总次数(Steps)变成了原来的 1/4。步数大幅减少,导致模型在同样的数据遍历次数下,还没走到最优解,所以需要跑更多的 Epoch。
2. “学习率调大(验证集损失跳)”
现象本质: 为了弥补上述“更新步数变少”的问题,Facebook(Meta)在 2017 年提出了著名的线性缩放法则(Linear Scaling Rule):当 Batch Size 乘以 $k$ 倍时,学习率也应该乘以 $k$ 倍。步数少了,那我们就在每一步迈得跨度更大一点。
为什么会跳(Loss Spike)? 如果你直接把学习率放大 4 倍甚至 8 倍,在训练初期,模型权重还是随机初始化的混乱状态,这时候直接迈极其巨大的步子,梯度会瞬间爆炸,导致验证集(甚至训练集)损失剧烈震荡、跳跃,甚至直接报
NaN(梯度飞出边界)。工程解法: 必须配合 学习率预热(Learning Rate Warmup)。即在最初的几个 Epoch 里,学习率不直接设为最大值,而是从 0 慢慢爬升到放大的目标值,等模型稍微稳定了,再大步狂奔。
3. “有可能精度变低(理论精度不变)”
现象本质: 这被称为大批量训练的泛化鸿沟(Generalization Gap)。即便训练集的 Loss 降到了和单卡一样低,测试集/验证集的精度依然会下降(通常掉点 1%~2%)。
背后的理论(尖锐极小值 Sharp Minima): * 小 Batch Size 算出的梯度带有很大的随机噪声,这种噪声反而是一种很好的正则化手段,它能帮模型跳出那些极其狭窄、尖锐的局部最优坑,最终落在地势平缓宽阔的谷底(Flat Minima)。平缓的谷底意味着即使测试集数据有一点点偏差,Loss 也不会变得很高(泛化好)。
- 大 Batch Size 算出的梯度非常“准”,它会笔直地冲向最近的局部最优解。但这个最优解往往是一个非常陡峭的窄坑(Sharp Minima)。只要测试集稍微有一点偏离,Loss 就会瞬间飙升,导致精度变低。
4. “所以需要考虑并行所花时间与非并行所花时间”
终极算账: 这是一个极其清醒的工程思维。引入并行是有通信开销的(如前所述,卡之间要等),且大 Batch 导致需要更多的 Epoch 才能弥补泛化鸿沟。
是否划算的数学公式:
假设单卡跑 1 个 Epoch 耗时 10 小时,需要跑 100 个 Epoch,总耗时 1000 小时。
现在用 4 张卡并行,因为通信损耗,单 Epoch 耗时变成了 3 小时(不是完美的 2.5 小时)。但因为大 Batch 的泛化问题,现在需要跑 150 个 Epoch 才能达到原精度。
最终耗时 = $150 \times 3 = 450$ 小时。
结论:450 小时 < 1000 小时,并行依然是赚的,但绝对没有你想象的赚了 4 倍那么多。 工程师的日常,就是在这个天平上不断寻找
Batch Size、Learning Rate和Epoch的最佳平衡点。
但在大数据集时并行效果好
数据增广(Data Augmentation,又称数据增强—正则化)
如果训练数据不够,模型就一定会走向过拟合(Overfitting)——即死记硬背训练集,而在真实的测试集中表现糟糕。
只改变方差,不改变均值
在图像处理中,数据增广主要分为三大流派:几何变换、色彩/光照变换、以及高级擦除/混合技术。
1. 几何变换(Geometric Transformations)
这是最基础的增广方式,它不改变图像的像素值分布,只改变像素的空间位置。它能赋予模型极强的空间不变性。
随机翻转(Random Flip): 最常用的是水平翻转。一张向左看的猫的图片,翻转后变成向右看,它依然是一只猫。
随机旋转(Random Rotation): 轻微旋转图像(如 $\pm 15^\circ$)。在现实中,人们拍照的手机往往是倾斜的。
随机裁剪与缩放(Random Resized Crop): 这是 Inception 网络带火的神技。先在原图上随机切下大小不一、长宽比不一的一块区域,然后再把它强制拉伸缩放回标准的输入尺寸(如 $224 \times 224$)。这逼迫网络有时看局部(猫的耳朵),有时看全局(整只猫)。
2. 光度学变换(Photometric Transformations)
现实世界的光照条件千变万化,我们需要让模型对光线“脱敏”。
色彩抖动(Color Jitter): 随机改变图像的亮度(Brightness)、对比度(Contrast)、饱和度(Saturation)和色相(Hue)。
随机灰度化(Random Grayscale): 以一定的概率(如 20%)将彩色图像变成黑白图像。这能强迫模型去学习物体的“形状”和“纹理”,而不是死死盯住物体的“颜色”不放。
3. 高级特征遮挡与混合(Advanced Augmentation)
这是近年来极其火爆的进阶技术。
随机擦除 / Cutout(Random Erasing): 在图像上随机选一块矩形区域,直接用纯黑色或随机像素覆盖掉。目的: 防止模型过度依赖某个局部特征。比如识别狗,如果总是只看狗头,一旦狗头被遮挡网络就瞎了;用了 Cutout,网络就被迫去学习狗的尾巴、身躯等其他特征。
Mixup / CutMix: 这是属于“魔法”范畴的增广。直接把两张不同的图片(比如一张猫和一张狗)按比例叠加上一起,标签也按比例混合(比如 0.6 的猫 + 0.4 的狗)。这极大地平滑了决策边界。
⚠️ 核心考点: 就像 BatchNorm 一样,数据增广只在训练阶段(Training)开启。在测试或推理阶段(Inference),我们希望评估的是模型最真实的性能,因此只会做尺寸对齐(如 CenterCrop)和标准化,绝对不会加入随机翻转或颜色抖动。
微调(Fine-tuning)
迁移学习
**核心逻辑:源数据集 $\rightarrow$ 目标数据集(10倍以上)
源数据集(Source Dataset): 通常极其庞大、标注成本极高。比如计算机视觉领域的 ImageNet(120万张图,1000个分类),或者 NLP 领域的超大规模互联网语料(几万亿个 Token)。在源数据集上训练出来的模型,我们称为预训练模型(Pre-trained Model)。
目标数据集(Target Dataset): 我们实际工程中面临的特定任务。比如“识别显微镜下的癌细胞”、“判断这句评论是不是在骂人”或“识别自家的宠物狗”。这些数据往往数量少(可能只有几百张)、获取成本高。
特征分布的黄金铁律(冻结层的理论依据):
底层(通用): 提取物理细节(边缘、角点、色彩过渡)。这些特征在所有视觉任务中通用,迁移时通常最需要被保护(冻结)。
高层(具体): 提取高级语义(特定动物、具体部件)。这些特征与源任务高度绑定,迁移到新任务时通常最需要被打破与重塑(解冻训练)。
三大主流微调策略:
策略 1:线性探测(Linear Probing / 特征提取器)
场景: 目标数据集极小,但和源数据集很相似。 做法: 冻结(Freeze)前面所有的卷积层,把它们当成一个纯粹的“通用特征提取器”,绝对不更新它们的权重。只把最后一层全连接层替换掉,并仅仅训练这最后一层。
策略 2:解冻顶部几层(Partial Fine-tuning)
场景: 目标数据集中等偏小,或者和源数据集差异较大(比如医学影像)。 做法: 冻结提取通用特征的底层,解冻靠近顶部的高层卷积和全连接层。因为底层边缘特征通用,可以直接用;但高层语义必须打破重建,以适应全新的特定领域。
策略 3:全局微调(Full Fine-tuning)
场景: 目标数据集足够大。 做法: 解冻所有的层,用目标数据集对整个网络进行端到端的训练。 ⚠️ 极其关键的细节: 既然是微调,说明我们信任它原本的权重。因此全局微调时,学习率(Learning Rate)必须设置得非常小(通常比从头训练小 10 到 100 倍,比如 lr=1e-4),否则过大的学习率会瞬间“洗脑”并破坏掉预训练模型原本极其优秀的通用特征权重。
目标检测
在目标检测中,我们用一个**边界框(Bounding Box, 简称 BBox)**来框住目标。
在数学上,一个边界框通常由 4 个数字来定义,最常见的两种表示方法是:
左上角与右下角坐标: $(x_{min}, y_{min}, x_{max}, y_{max})$
中心点与宽高: $(x_{center}, y_{center}, width, height)$
深度学习模型的任务,就是通过输入一张图片,不仅输出类别的概率(这是猫还是狗),还要回归预测出这 4 个坐标数字。
锚框(Anchor Boxes)
痛点: 让神经网络直接凭空猜出一张图片里所有物体的 $x, y, w, h$ 坐标是非常困难的。因为物体的尺寸千变万化,有的像电线杆一样细长,有的像汽车一样扁平。
锚框的破局之道:
既然凭空猜很难,那我们就在图片上密密麻麻地铺满各种尺寸、各种比例的“模板框”。这些模板框就是锚框。
预设模板: 工程师会预先设定好几种固定的宽高比(比如 1:1, 1:2, 2:1)和不同的缩放尺度。
铺满全图: 以特征图上的每一个像素点为中心,放置这些不同形状的锚框。
将“凭空猜测”变成“微调”: 神经网络不再直接预测物体的绝对坐标,而是去判断:“这只猫与哪个锚框最匹配?在这个最匹配的锚框基础上,我需要把它的中心点挪动多少?宽和高需要放大或缩小多少比例?”
交并比(IoU - Intersection over Union)
无论是评估模型预测的框准不准,还是在后续处理冗余框时,我们都需要一个能衡量**“两个框到底有多重合”**的数学指标。这就是 IoU。
公式计算极其简单直观:
$$IoU = \frac{\text{两个框的交集面积 (Intersection)}}{\text{两个框的并集面积 (Union)}}$$
取值范围: 0 到 1 之间。
IoU = 0: 两个框完全没有挨着。
IoU = 1: 两个框严丝合缝地完全重叠。
业界标准: 通常当模型预测框与真实框(Ground Truth)的 $IoU > 0.5$ 时,我们就认为这个目标被成功检测到了。
为什么不用欧式距离算中心点?
因为具有尺度不变性。两个大框偏离 10 个像素,依然能框住大部分物体;但两个小框如果偏离 10 个像素,可能就完全错开了。IoU 完美地消除了物体绝对尺寸带来的误差影响。
非极大值抑制(NMS)
痛点: 既然我们在图片上铺了成千上万个锚框,那么对于同一个物体(比如画面中央的一辆车),模型很可能会输出几十个稍微错开、但都框住了这辆车的预测框。 如果不处理,你的检测结果看起来就像是被一团乱麻包裹住了。
NMS 的使命: 找出同一个物体上最准的那个框,然后把其他重叠的冗余框全部删掉(抑制掉)。
NMS 的算法运作流程(纯逻辑,不涉及参数学习):
排序: 将模型输出的所有预测框,按照**置信度得分(Confidence Score,即模型觉得这个框里有物体的概率)**从高到低排序。
选“王”: 挑选出当前列表中得分最高的那个框,把它放入“最终保留列表”中。
“连坐”清除: 计算列表中剩下的所有框与这个“王”框的 IoU。如果某个框的 IoU 大于设定的 NMS 阈值(比如 0.5),说明它和“王”框住的是同一个物体,直接将它从列表中删除(抑制)。
循环: 在剩下的框里,再挑出得分最高的作为新的“王”,重复步骤 3,直到列表被清空。
如果两个框的重合度(IoU)超过了设定的阈值,我就认为它们框住的是同一个东西,把得分低的那个删掉。
场景一:阈值设得太高(比如 0.9)—— 判罚太宽容,导致“假阳性”
逻辑原理: 阈值 0.9 意味着,只有当两个框的重合度达到了 90% 及以上时,系统才会把其中一个删掉。如果重合度只有 80%,系统就会认为:“这俩框重合度不够高,它们框住的肯定是两个不同的物体,我都保留下来。”
现实灾难: 假设画面正中央只有一辆车。模型在预测时,通常会在车周围生成好几个预测框。这些框可能左边偏了一点,右边偏了一点。它们之间的重合度可能是 70% 或 80%。
结果: 因为你的阈值是 0.9,系统觉得 70% 的重合度不足以触发“删除”机制。于是,这辆车上最终会套着 3、4 个框。明明只有一辆车,系统却输出了多个检测结果,这就是假阳性(False Positive)。
场景二:阈值设得太低(比如 0.1)—— 判罚太严厉,导致“漏检”
逻辑原理: 阈值 0.1 意味着,只要两个框稍微碰上一点点(重合度超过 10%),系统就会武断地认为:“只要挨着了,就绝对是同一个物体,立刻把得分低的那个框干掉!”
现实灾难: 假设地铁站里有两个乘客肩并肩站得非常近。模型很精准地找出了他们,给了乘客A一个框(得分 0.95),给了乘客B一个框(得分 0.90)。由于两人站得很近,这两个真实框在画面上会有大概 20% 的重叠区域(胳膊挨着胳膊)。
结果: 因为你的阈值是 0.1,系统发现重合度 20% > 10%,触发了“删除”机制!它直接把得分稍低的乘客B的框给删了。明明有两个活生生的人,系统却只输出了一个人,另一个人被无情地“抑制”掉了,这就是漏检(False Negative)。
目标检测算法
R-CNN 是早期经典的两阶段目标检测算法,它先利用选择性搜索生成候选区域,再对每个区域用 CNN 提取特征并分类,因此精度较高但速度较慢。
Fast R-CNN 通过让整张图只进行一次卷积计算,并引入 RoI Pooling 将不同大小的候选区域映射为固定尺寸特征,从而显著提高了检测效率。
Mask R-CNN 在 Faster R-CNN 基础上增加了像素级 mask 分支,并使用 RoI Align 提升定位精度,实现了实例分割。
SSD 和 YOLO 属于单阶段检测算法,直接从整张图中同时预测目标类别和边界框,速度快,适合实时场景。
CenterNet 是典型的无锚框检测算法,它通过预测目标中心点、宽高和偏移量完成检测,结构更简洁,减少了锚框设计的复杂性。这些模型广泛应用于无人车感知系统中,用于检测车辆、行人、交通灯和障碍物等目标。
R-CNN:区域卷积神经网络(Region-based CNN)
在 R-CNN 之前,目标检测一般靠人工特征 + 传统分类器。
R-CNN 的核心想法是:先找出图中“可能有目标的区域”,再对这些区域逐个用 CNN 分类。
它把目标检测拆成了两步:
**第一步:候选区域生成
先用一种传统方法,叫 Selective Search(选择性搜索),从一张图中提出大约 2000 个“候选框”。这些候选框是“可能有物体的地方”。
**第二步:逐区域分类
把每个候选框裁剪出来,缩放成统一大小,再送进 CNN 提取特征,最后用 SVM 分类器判断这是:
- 人
- 车
- 狗
- 背景
同时用边界框回归进一步修正框的位置。
**原图 → Selective Search 生成候选区域 → 每个区域缩放 → CNN 提特征 → SVM 分类 → 边框回归修正
问题
(1)候选框太多
每张图约 2000 个候选区域。
(2)每个候选框都单独跑一次 CNN
这意味着大量重复计算。
同一张图中,很多区域高度重叠,但 CNN 却一遍遍重复提特征。
(3)训练流程复杂
R-CNN 不是端到端训练,而是分多个阶段:
- 先训练 CNN
- 再提特征
- 再训练 SVM
- 再训练边框回归器
整个流程麻烦而且效率低。
RoI 池化层(RoI Pooling)
在检测任务中,不同候选框大小不同:但后续全连接层通常要求输入是固定维度。
于是问题来了:如何把不同大小的候选区域,统一变成固定大小的特征表示?
先让整张图只经过一次卷积网络,得到一张共享的特征图。
然后对于每个候选框,不再回到原图裁剪,而是在特征图上截取对应区域。
假设某个 RoI 在特征图上的区域大小是 10×7。
但后续网络需要固定大小,比如 7×7。
RoI Pooling 的做法是:
- 把 10×7 的区域划分成 7×7 个网格
- 每个网格里做最大池化
- 最终得到固定大小的 7×7 输出
这样,不管输入框大小如何,最后都能变成固定尺寸的特征。
优点
(1)避免重复卷积计算
整张图只做一次 CNN。
(2)统一不同候选框大小
方便后续分类和回归。
(3)大幅提高速度
这是 Fast R-CNN 比 R-CNN 快很多的重要原因。
缺点
RoI Pooling 需要把浮点坐标离散化、量化。
这会导致:
- 特征与原图位置对不齐
- 边界定位误差
- 对像素级任务不够精确
这也是后来 RoI Align 出现的原因。Mask R-CNN 就用 RoI Align 替代了 RoI Pooling。
Fast R-CNN
**整张图只做一次卷积,然后在共享特征图上对每个候选区域做 RoI Pooling。
原图 → CNN 提取整图特征图 → 候选框映射到特征图 → RoI Pooling → 全连接层 → 分类 + 边框回归
候选框仍依赖 Selective Search,而这一步很慢。
所以后来才出现了 Faster R-CNN,用区域建议网络 RPN 直接学习产生候选框。
Mask R-CNN
Mask R-CNN 是在 Faster R-CNN 基础上扩展出来的,主要用于:
实例分割
它不只预测:
- 类别
- 边界框
还额外预测: - 每个目标的像素级 mask
Mask R-CNN 是在 Faster R-CNN 的基础上,又并联加了一个分支:不仅输出边界框,还输出像素级的实例分割掩码(Mask)。并且,它将 RoI Pooling 升级成了精读更高的 RoIAlign(消除了量化误差,对齐到亚像素级别)。
在无人车中的降维打击: 传统的框(BBox)在自动驾驶中是不够用的。比如一辆大卡车斜着停在路边,它的检测框会非常大,甚至覆盖了旁边的车道。如果只看框,自动驾驶系统会认为旁边的车道被占用了,不敢变道。
Mask R-CNN 的价值: 它能精确勾勒出卡车的物理轮廓边缘,无人车系统就能明确知道:“虽然框很大,但像素掩码显示那个角落是空的,可以安全通行。”这对于行人避让、可行驶区域提取至关重要。
YOLO (You Only Look Once)
单阶段
运作逻辑: YOLO 将整张图片强行划分为 $S \times S$ 的网格(Grid)。它的规矩非常霸道:物体的中心点落在哪个网格,那个网格就负责检测这个物体。 每个网格直接预测出几个边界框的坐标、置信度以及类别概率。
特点: 因为没有了寻找候选框的繁琐步骤,YOLO 把目标检测变成了一个纯粹的回归问题,速度极快,是工业界实时检测(如视频流监控、无人机视角)的绝对王者。
单发多框检测 (SSD - Single Shot MultiBox Detector)
YOLO 的痛点: 早期的 YOLO 因为网格比较粗糙,对小目标(比如远处的交通锥)检测极差。
SSD 的解法(特征金字塔的雏形): SSD 结合了 YOLO 的单阶段速度,以及不同网络层级的优势。CNN 浅层的特征图分辨率高,适合抓小物体;深层的特征图分辨率低、感受野大,适合抓大物体。
运作逻辑: SSD 直接在 CNN 的多个不同尺度的特征图上,同时铺设不同大小的锚框(Anchor Boxes)进行独立预测,最后把结果汇总。这极大地提升了多尺度目标的检测精度。
基于非锚框(Anchor-Free)的算法 CenterNet
无论是 Faster R-CNN 还是 YOLO/SSD,它们都严重依赖“锚框(Anchor)”——你需要手动设置很多框的比例(长宽比 1:1, 1:2 等)。这不仅增加了调参的恶梦,还导致正负样本极度不平衡(99% 的锚框都是背景)。
革命性颠覆: 为什么要画框?一辆车、一只猫,不就是一张图上的一个中心点吗?
运作逻辑: CenterNet 完全抛弃了锚框。它通过输出一张**“中心点热力图(Heatmap)”**,直接预测物体的中心点位置。当找到这个中心点最高亮(概率最大)的地方后,网络再顺便预测出这个点的两个属性:**物体的宽度和高度(W, H)**以及局部偏移量。
极简的美学: 因为一个物体只有一个峰值中心点,它甚至**不需要使用 NMS(非极大值抑制)**来清理冗余框,直接用一个简单的 $3 \times 3$ 最大池化就能提取中心点。速度和精度都达到了极其优雅的平衡。
语义分割(Semantic Segmentation)
核心任务: 将图像中的每一个像素分配给一个预定义的类别标签(如:人、车、道路、天空、树木)。
工作逻辑: 语义分割就像是一个极其死板的分类器。它遍历图片上的每一个像素,问自己:“这个像素属于什么类别?”
致命盲点: 它无法区分同类别的不同个体。假设图片里有两只紧紧挨在一起的羊,语义分割模型会把这两只羊所在的像素全部涂成相同的颜色(比如代表“羊”的红色)。在模型的输出结果里,你只能看到一大块红色的“羊肉团”,根本数不清这里到底有几只羊。
实例分割(Instance Segmentation)
核心任务: 它是目标检测(Object Detection)与语义分割的终极结合体。它不仅要精确到像素级别,还要把同一个类别下的不同个体区分开来。
工作逻辑: 实例分割通常是“先找人,再抠图”。它首先像目标检测一样,用框找出所有的“羊”和“人”,然后再在每个框内部,进行极其精细的像素级二分类(判断这个像素是前景物体,还是背景)。
完美视力: 如果有两只紧紧挨在一起的羊,实例分割会明确地告诉你:这是“羊A”(涂成红色),那是“羊B”(涂成绿色),即使它们的毛贴在一起,边界也会被清晰地划开。
适用场景: 需要精确计数和追踪个体的场景。例如:
自动驾驶中的行人/车辆避让: 必须精确知道前面有几辆车、几个人,它们的精确轮廓是什么,绝对不能把几个人当成一个大方块。
机器人抓取: 在一堆堆叠的零件中,机器人必须精确知道每一个独立零件的边缘,才能计算抓取点。
安防监控: 精确追踪人群中的特定个体。
经典网络架构:
- Mask R-CNN: 绝对的统治者。在 Faster R-CNN(目标检测)的基础上,并联增加了一个极其轻量级的卷积分支(FCN),专门用于在检测框内部生成像素级掩码(Mask)。
全景分割(Panoptic Segmentation)
如果你觉得实例分割已经很强了,学术界还有个更贪心的终极任务:全景分割。
语义分割专注于“背景/材质(Stuff)”(如天空、草地、道路)。
实例分割专注于“前景/个体(Things)”(如人、车、动物)。
全景分割 = 语义分割 + 实例分割。它要求模型在同一张图里,既要把背景(天空、道路)进行像素级语义分类,又要把前景(人、车)进行个体级别的实例分割,实现真正意义上的“像素级大一统”。
转置卷积
它是一种能够学习如何把低分辨率特征图映射到高分辨率特征图的线性运算,其矩阵形式与普通卷积对应矩阵的转置有关,所以叫转置卷积。它广泛应用于图像生成(GAN)、语义分割(U-Net)、图像超分辨率(Super-Resolution)、风格迁移等需要将低分辨率特征图恢复为高分辨率的任务中。
转置卷积是一种用于上采样的卷积型运算。
它的作用通常是:
把较小的输入特征图,映射成较大的输出特征图。
- 标准卷积可以表示为矩阵乘法:$$y=Wx $$,其中$W$ 是由卷积核构造的稀疏 Toeplitz 矩阵,$x$ 是展平后的输入向量,$y$ 是输出。
- 转置卷积则是该操作的转置:$$y′={W}^Tz$$ ,其中 ${z}$ 是低维输入(小特征图),y′′ 是高维输出(大特征图)。
- 它不是数学意义上的逆卷积(inverse convolution),因为标准卷积通常不可逆(信息丢失)。在深度学习中,“Deconvolution”只是历史叫法,实际实现是卷积的伴随操作(adjoint),对应反向传播中的梯度计算。
| 方面 | 标准卷积 (Conv) | 转置卷积 (Transposed Conv) |
|---|---|---|
| 作用 | 下采样、特征提取、缩小尺寸 | 上采样、特征展开、扩大尺寸 |
| 输入→输出尺寸 | 通常缩小(stride > 1 时) | 通常扩大(stride > 1 时) |
| 操作本质 | 核在输入上滑动,聚合邻域信息 | 每个输入像素“扩张”成一块区域,叠加贡献 |
| 输出尺寸公式 | $o=⌊(i+2p−k)/s⌋+1$ | $o=(i−1)×s−2p+k+dp$ |
| 典型用途 | Encoder、特征提取 | Decoder、生成器 |
| 其中: |
- i: 输入尺寸
- k: 核尺寸(kernel_size)
- s: 步长(stride)
- p: 填充(padding)
- dp: 输出填充(output_padding,通常 0 ~ s−1 s-1 s−1)
转置卷积的核心思想是:将输入的每个元素“拉伸”到输出空间,并用卷积核加权后叠加。

全卷积网络FCN(Fully Convolutional Network)
它把原本用于图像分类的卷积神经网络改造成了可以进行像素级预测的网络,从而让卷积神经网络能够直接用于语义分割任务。
提出背景
在 FCN 之前,卷积神经网络主要用于图像分类,例如 AlexNet、VGG 等模型。
这些模型的特点是:
- 前面使用卷积层提取特征
- 后面使用全连接层输出类别概率
这种结构适合做“整张图分类”,但不适合做语义分割。原因在于:
1. 全连接层会丢失空间结构
全连接层把二维特征图展平成一维向量,空间位置信息被严重压缩,不利于像素级预测。
2. 分类任务只需要一个类别输出
而语义分割需要对每一个像素输出类别。
3. 传统分割方法效率低
在 FCN 出现前,有些方法会对图像块逐块分类,也就是对每个像素周围的小区域单独送入 CNN。这种方法有两个问题: - 计算重复非常严重
- 推理速度很慢
于是研究者提出了一个关键想法:
能不能让网络一次输入整张图,一次输出整张图的像素分类结果?
核心思想
把传统分类网络中的全连接层替换成卷积层,使网络可以接受任意大小输入,并输出对应大小的空间预测图。
这里有两个关键点:
1. 全连接层改为卷积层
传统分类网络最后通常是全连接层,例如:
- FC6
- FC7
- FC8
FCN 将这些层改写成卷积层。这样做之后,网络不再只能输出一个固定长度向量,而是可以输出一个二维空间特征图。
2. 使用上采样恢复分辨率
由于卷积和池化会不断减小特征图尺寸,所以 FCN 需要通过上采样,把低分辨率特征图恢复到接近输入图像大小,从而实现像素级分类。
所以 FCN 的本质就是:
卷积提特征 + 卷积输出类别图 + 上采样恢复分辨率
“全卷积”这个名字的意思是:
整个网络中不再使用全连接层,而是全部由卷积相关操作组成。
这里的“全部”主要指带参数的核心层:
- 卷积层
- 由全连接层改写而来的卷积层
- 上采样层
FCN 做的是逐像素分类,所以它的损失函数一般是 逐像素交叉熵损失。
假设图像中一共有 $N$ 个像素,每个像素的真实类别是 $y_i$,预测概率为 $p_i$,那么损失可以写成:
$$L = -\sum_{i=1}^{N} \log p_i(y_i)$$
这和普通分类的交叉熵类似,只不过这里不是对整张图做一次分类,而是对每个像素都做分类。
为了缓解深层特征语义强但定位粗糙的问题,FCN 还引入了跳跃连接,将浅层高分辨率特征与深层语义特征融合,形成了 FCN-32s、FCN-16s 和 FCN-8s 等结构。
样式迁移(Style Transfer)
样式迁移是计算机视觉中一个非常经典的图像生成任务。它的目标是:
将一张图像的内容(content)与另一张图像的艺术风格(style)结合起来,生成一张既保留原图内容、又具有目标风格的新图像。
内容关注的是:图像的高层语义结构和主要形状。
风格关注的是:图像的外观表现形式,而不是具体画了什么。
样式迁移的核心任务就是:
内容图像+风格图像→风格化结果图像
样式迁移真正被广泛关注,是因为 2015 年 Gatys 等人提出了经典的 Neural Style Transfer 方法。这个工作非常重要,因为它提出了一个核心观点:卷积神经网络中不同层的特征可以分别表示图像的内容和风格。
在此之前,人们更多把 CNN 当成分类器。
而样式迁移告诉我们:
- CNN 浅层特征能表示纹理、颜色、局部模式
- CNN 深层特征能表示高层内容结构
- 因此可以利用不同层特征来定义“内容损失”和“风格损失”
生成一张新图像,使它在高层特征上接近内容图像,在纹理统计特征上接近风格图像。
内容通常通过某个深层卷积特征图来表示。
风格通常通过多个卷积层特征之间的统计关系来表示,最经典的方法是使用 Gram Matrix(格拉姆矩阵)
Gram 矩阵描述的是:不同通道特征之间的相关性。—协方差
经典方法一般使用一个预训练好的卷积神经网络,例如 VGG-19。
注意,这个网络不是拿来重新训练分类器,而是作为一个固定的特征提取器。
整体流程如下:
内容图像、风格图像、生成图像→输入预训练CNN→提取特征→计算内容损失和风格损失→更新生成图像
内容损失
假设在某一层提取到:
- 内容图像特征:$F^l$
- 生成图像特征:$P^l$
那么内容损失通常定义为两者之间的平方误差:
$$
L_{\text{content}} = \frac{1}{2} \sum_{i,j} (F^l_{ij} - P^l_{ij})^2$$
这里的含义是:
- 如果生成图像在这一层的高层特征和内容图像很接近
- 那么它们的结构和语义布局也比较接近
内容损失越小,说明生成图像越保留内容图像的主要结构。
Gram 矩阵
对于某一层特征图,假设它被 reshape 成矩阵:
$$
F^l \in \mathbb{R}^{N_l \times M_l}$$
其中:
- $N_l$ 是通道数
- $M_l$ 是每个通道中空间位置数
那么该层的 Gram 矩阵定义为:
$$G^l_{ij} = \sum_k F^l_{ik} F^l_{jk}$$
它表示: - 第 $i$ 个通道和第 $j$ 个通道之间的相关程度
可以把 Gram 矩阵理解为:这一层特征模式之间的共现统计。
这种统计关系能够反映风格中的: - 纹理
- 笔触组织
- 重复图案
- 色彩结构
风格损失
如果:
- 风格图像在第 $l$ 层的 Gram 矩阵是 $A^l$
- 生成图像在第 $l$ 层的 Gram 矩阵是 $G^l$
那么该层风格损失可定义为:
$$E_l = \frac{1}{4N_l^2 M_l^2} \sum_{i,j} (G^l_{ij} - A^l_{ij})^2$$
总风格损失一般是多个层加权求和:
$$L_{\text{style}} = \sum_l w_l E_l$$
其中:
- $w_l$ 表示第 $l$ 层风格损失的权重
这表示我们希望生成图像在多个层级上都接近风格图像的纹理统计特征。
总损失函数
经典神经样式迁移的总损失一般由三部分组成:
$$L_{\text{total}} = \alpha L_{\text{content}} + \beta L_{\text{style}} + \gamma L_{\text{tv}}$$总变差损失(Total Variation Loss)通常用于让图像更平滑,减少噪声和局部不自然波动。
一个常见形式为:
$$L_{\text{tv}} = \sum_{i,j} \left((x_{i,j+1} - x_{i,j})^2 + (x_{i+1,j} - x_{i,j})^2\right)$$
它的作用是:
- 抑制高频噪声
- 让输出更平滑自然
- 提高视觉质量